

I. Basic Concept of Inter-Services Communication in Microservices
In microservices architecture, microservices can communicate with each other in several different ways; at least three common techniques are usually used in inter-service communication:
HTTP-based Communication
In this inter-service communication, the service will call the service destination directly through HTTP protocol and usually the service caller will get the service response immediately; either the success response or error response. Usually, the HTTP-based communication is a synchronous communication where the service caller will block the next step until the service invocation is already completed, as you can see in picture 1.
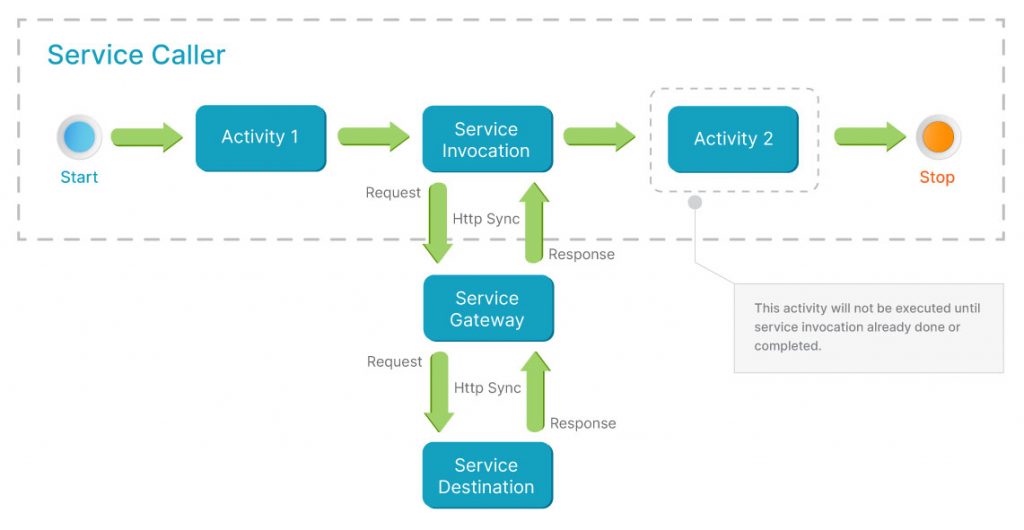
When planning to implement synchronous inter-service communication in our microservices, we should consider several circumstances where the service’s destination may be down or in poor performance or slow response as these circumstances will lead to serious performance problems with the caller services if they do not configure or cannot handle these circumstances. For example, the service caller invokes one service which is down or in poor performance. If the caller service is not prepared for these circumstances, the caller services will have to wait for service invocation to be completed; and what will happen if tens or hundreds of thousands or transactions or more hit this caller service?
The best practice to deal with these circumstances is to add a circuit breaker for each service invocation. The example of synchronous inter-service communication in spring boot-based application is service invocation using Rest Template as we can see in code snapshot below.

In addition to synchronous inter-service communication, in http-based communication, we can make the service invocation in http-based communication asynchronous. There are several frameworks in java that can be used for that purpose. For example, we can use Future to wrap service invocation in one method (https://spring.io/guides/gs/async-method/) as we can see in the code snapshot below.
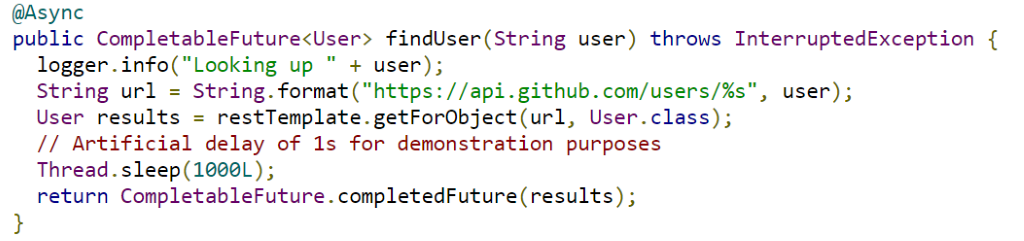
Source: https://spring.io/guides/gs/async-method/
We can show the method above in an asynchronous method as shown below:
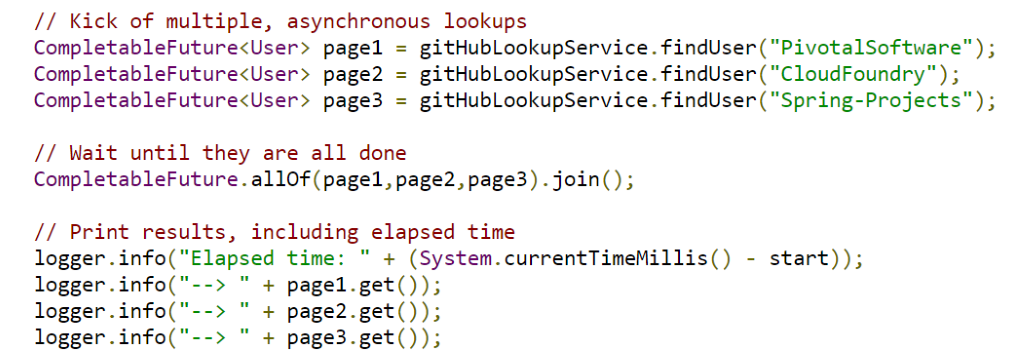
Source: https://spring.io/guides/gs/async-method/
With asynchronous communication, there is no blocking call when handling service invocation; the service caller will get the response through the call-back. Unlike synchronous inter-service communication, asynchronous inter-service communication will keep the services isolated from other services and loosely coupled.
Messaging-based Communication
Another communication technique is message-based communication. This technique is commonly used in Enterprise Application Integration to make the integration loosely coupled and asynchronous. Messaging-based communication is also the best choice to make our application resilient and scalable. In messaging-based communication, we usually use a message broker to manage and process the message sent by the producer and it can be persisted if required; the message broker will guarantee message delivery. With a message broker, the communication will be asynchronous. Commonly, there are two options in message-based communication:
- Point to Point
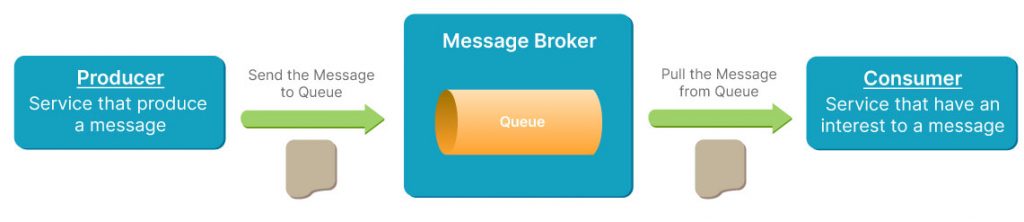
A queue will be used for this type of messaging-based communication. The service that produces the message, which is called as producer (sender), will send the message to a queue in one message broker and the service that has an interest in that message, which is called a consumer (receiver), will consume the message from that queue and carry out further processes for that message as shown in picture 5. One message sent by a producer can be consumed by only one receiver and the message will be deleted after consumed. If the receiver or an interested service is down, the message will remain persistent in that queue until the receiver is up and consumes the message. For this reason, messaging-based communication is one of the best choices to make our microservices resilient.
With some workaround, we can make this communication synchronous (request-response pattern) using ActiveMQ message broker as described in https://activemq.apache.org/how-should-i-implement-request-response-with-jms.
- Publisher-Subscriber
In publisher-subscriber messaging-based communication, the topic in the message broker will be used to store the message sent by the publisher and then subscribers that subscribe to that topic will consume that message as shown in picture 6. Unlike point to point pattern, the message will be ready to consume for all subscribers and the topic can have one or more subscribers. The message remains persistent in a topic until we delete it.
There are several open-source message brokers that we can use in messaging-based communication such as ActiveMQ, RabbitMQ, Apache Kafka etc. Each of the message brokers have pros and cons depending on the application requirement. For example, apache Kafka has a publishing speed of 165K messages/second over single thread and a consuming speed of 3M messages/second (https://dzone.com/articles/exploring-message-brokers) but apache Kafka does not support queue-based communication (point to point pattern) and mostly topic-based communication (publisher-subscriber pattern). There is no one message broker that is fit for every project or application, each has its own strengths and weaknesses. We can choose a message broker that fits with our requirements based on features, pros and cons: https://blog.scottlogic.com/2018/04/17/comparing-big-data-messaging.html https://dzone.com/articles/exploring-message-brokers.

In messaging-based communication, the services that consume messages, either from queue or topic, must know the common message structure that is produced or published by producer or publisher.
Another messaging-based communication commonly used is event-based communication. Unlike messaging-based communication, in event-based communication, especially in event-driven pattern (https://microservices.io/patterns/data/event-driven-architecture.html), the services that consume the message do not need to know the details of the message. In event-driven pattern, the services just push the event to the topic in the message broker and then the services that subscribe to that topic will react for each occurrence event in that topic as shown in picture 7. Each event in the topic will be related to a specific business logic execution.
In addition to event-driven pattern, event-based communication is usually used as event-sourcing in CQRS pattern, the pattern that makes a separation between write operation (insert/update/delete) and read operation (select). The message broker is commonly used as an event store when we are going to implement CQRS pattern in microservices. We can explore more details about CQRS and how to implement it using spring boot and axon framework in the following URL: https://medium.com/@sderosiaux/cqrs-what-why-how-945543482313 & https://medium.com/@berkaybasoz/event-sourcing-and-cqrs-with-axon-and-spring-boot-part-1-6d1c1d4d054e.

II. Kafka Introduction
Kafka is a highly scalable messaging system that was developed by Linkedin’s software engineer to manage various streaming and queueing data in the LinkedIn application when they decided to re-design their monolithic infrastructure to a microservices infrastructure, and in 2011, LinkedIn open-sourced Kafka via Apache Software Foundation.
Kafka uses pub-sub pattern in its messaging system. A message published by the producer can be consumed by one or more consumers that subscribe to its topic. Before we use Kafka, there are several terms we must familiar with:
- Zookeeper
Zookeeper is required for running Kafka; it has responsibility to manage topic configuration, the topics access control list, cluster membership and the coordinate Kafka cluster. - Broker
Broker is an instance of Kafka; the topics are created inside the broker. - Topics
Topics is the place where publishers push the messages and subscribers pull the messages. - Partition
Kafka topics can be divided into several partitions and Kafka stores the messages within the partition identified. To make extremely high processing throughput, we can parallelize a topic by splitting the data in a topic across multiple brokers to allow multiple subscribers to read the message from a topic in parallel.
III. Asynchronous Communication with Apache Kafka
In this blog, we used Kafka as one of the inter-service communication methods in our microservices, especially for handling blog approval processes. Before we jump to how to use Kafka to make asynchronous inter-service communication, there is some preparation we need to do:
1. Zookeeper & Kafka Installation
Before we run Kafka, we must run Zookeeper first. Usually, zookeeper and Kafka have different binary installations; we can download zookeeper from https://zookeeper.apache.org/releases.html and Kafka from https://kafka.apache.org/downloads, but for simplicity reasons, we will use zookeeper that is included in Kafka installer kafka_2.12-2.5.0.
After we have downloaded Apache Kafka and extracted it, we set several configs in zookeeper properties and server and properties in KAFKA_HOME/config folder as shown below:

In the above config, we set zookeeper’s port where Kafka used it to connect to and the directory to store zookeeper data. In server properties, we set the folder location to store the Kafka log and zookeeper server that was required by Apache Kafka, as shown below:

After completing the config setup, we can run zookeeper first before we run the Kafka server as shown below:
KAFKA_HOME\bin\windows\zookeeper-server-start.bat
KAFKA_HOME\config\zookeeper.properties and then run the Kafka server using the following command:
KAFKA_HOME\bin\windows\kafka-server-start.bat KAFKA_HOME \config\server.propertiesIf we have a problem like “Input line is too long” when running the Kafka Server, we can solve that problem using a solution in this URL: https://narayanatutorial.com/jms/apache-kafka/the-input-line-is-too-long-the-syntax-of-the-command-is-incorrect.
To test that zookeeper and Kafka are running properly, we can use the Kafka Tool that can be downloaded from https://www.kafkatool.com/download.html. After we have downloaded and installed the tool, we open the tool and then click File -> Add New Connection sub-menu, and fill the zookeeper and Kafka server with our own details as shown below:
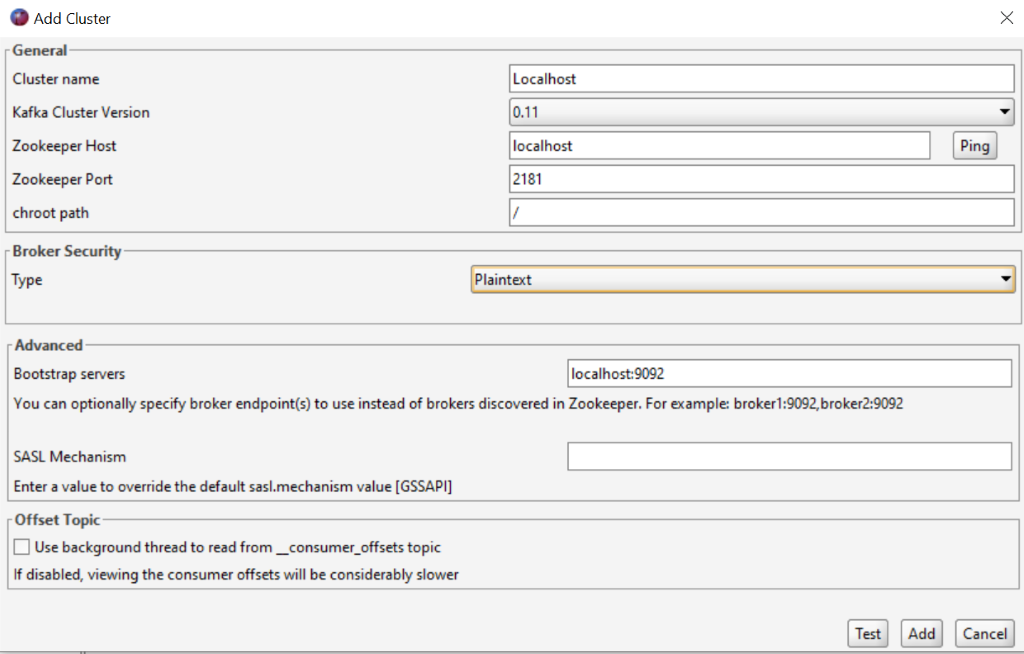
Next, the clicks Test button and then the Add button. After that, double click cluster name, for example localhost; the colour will change to green which means the tool can connect to the Kafka Server, as shown below:

In the above picture, if we can see the hostname where the Kafka Server is running in the Brokers’ child tree, the Kafka server is ready to use in our project.
2. Clone Case Study Project from GitHub
After we have set up the environment, now we need to clone the project from GitHub repository that will be used in this blog.
Backend:
- Service Registry: https://github.com/cdcbootcamp/service-registry.git
- Config Server: https://github.com/cdcbootcamp/configuration-server.git
- Blog Microservice: https://github.com/cdcbootcamp/blog-microservices.git
- Approval Microservice: https://github.com/cdcbootcamp/approval-service.git
- Blog-Config: https://github.com/cdcbootcamp/blog-config.git
Frontend:
https://github.com/cdcbootcamp/blog-frontend-application.git
In this project, we have used the spring cloud config server as an externalized config file. All of the project’s config file is stored in https://github.com/cdcbootcamp/blog-config.git and we also used jasypt library to encrypt the database password. Before running the projects, make sure you change the database password in all project’s config inside Blog-Config repo to your own encrypted password and hosting that config in your repository, do not forget to change the repo and its account in application.yml in Config Server repo.
3. Implement Apache Kafka in the Projects
Before discussing how to make asynchronous inter-service communication, we will look at project architecture. The projects implement microservices architecture as shown below:
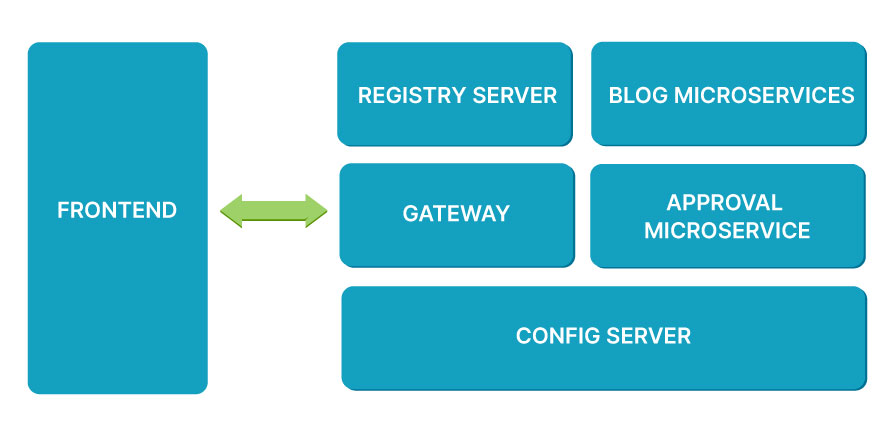
We will not discuss service registry gateways, we will just focus on interaction between the blog microservice and approval microservice. We used Kafka as a messaging system in the blog creation flow and blog approval process flow as well, as shown below:

In this blog, we just focus on inter-service communication in the red rectangle area. When we create Post using /posts API from the blog microservice and after the blog has been created and persisted into the database, the blog microservice will push the Post payload to the blog-creation topic in the Kafka message broker to request blog approval.
Then the approval microservice that subscribes to that blog-creation topic will pull the payload and persist it to the database with the approval_progres – “To Do”. Approval microservice will process approval request via /process API. There are three approval_progres values: To Do, In Progress and Done. To-Do is an initial state for every successfully created post, when the blog admin processes an approval request through frontend application, approval_progres will be updated to “In Progress” and when the blog admin either approves or rejects the blog, approval_progres will be updated to “Done” and approval microservice will push the payload that contains approval status to the blog-approval topic. Then blog microservice that subscribes to that blog-approval topic will pull the payload and will check the approval status. If approval status = Approved, blog status will be updated to true and otherwise to false. It is only all published blog with status true that will display on the Blog Home Page in the frontend application.
Now we will implement the explained flow into our project. Open the blog microservice project that we have cloned before; in that project, we used maven as project build management. Take a look at pom.xml; we must add dependency in our pom.xml if we want to use Kafka in our project as shown below:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
<version>3.0.0.RELEASE</version>
</dependency> We will not discuss other dependencies in pom.xml, we just focus on Kafka implementation. After we add Kafka dependency, we add several Kafka configs to create topic configuration, zookeeper and broker address in application.yml file as shown below:
spring:
cloud:
stream:
bindings:
BlogCreationOutput:
destination: blog-creation
content-type: application/json
BlogUpdateStatusInput:
destination: blog-approval
content-type: application/json
kafka:
binder:
zkNodes: localhost
brokers: localhost In the above config, we created one topic (blog-creation) to publish payload after the blog was created successfully and we defined one topic (blog-approval) that will be subscribed by blog microservice to receive the payload to update blog status. The content-type is the format of the message; we used json as payload format. zkNodes refers to zookeeper that is used by Kafka whereas brokers refers to Kafka. We left zookeeper and brokers without port if we set it in default configuration; in port 2181 for zookeeper and port 9092 for Kafka.
After we set up the config in the application.yml file, we create one interface in the com.mitrais.cdc.blogmicroservices.utility package to put in a Kafka operation like publish or subscribe, as shown below:
@Component
public interface KafkaCustomChannel {
@Input("BlogUpdateStatusInput")
SubscribableChannel blogUpdateStatusSubsChannel();
@Output("BlogCreationOutput")
MessageChannel blogCreationPubChannel();
} We put @Component in our interface, so the spring framework will create the implementation of this interface before the application is running and will inject it whenever this interface required. @Input notation is used for the subscriber to subscribe to one topic, for example the input notation above refers to “BlogUpdateStatusInput”. If we see this input notation in the application.yml file, it refers to the blog-approval topic. For publisher, we used @Output notation where in the above interface, the Output notation refers to “BlogCreationOutput”. If we see in application.yml file, that refers to the blog-creation topic. This interface will be used to push the message to the topic and BlogUpdateStatusInput will be used by a method that subscribes the topic to pull the message by using @StreamListener notation.
Next, we create a Kafka Service interface with its implementation as shown below:
public interface KafkaService {
void publishBlogCreationMessage(PostPayload postPayload);
} @Service
public class KafkaServiceImpl implements KafkaService {
private KafkaCustomChannel kafkaCustomChannel;
@Autowired
public KafkaServiceImpl(KafkaCustomChannel kafkaCustomChannel) {
this.kafkaCustomChannel = kafkaCustomChannel;
}
@Override
public void publishBlogCreationMessage(PostPayload postPayload) {
this.kafkaCustomChannel.blogCreationPubChannel().send(MessageBuilder.withPayload(postPayload).build());
}
} The publishBlogCreationMessage method is used to publish the payload to the blog-creation topic after the blog was created successfully by calling KafkaCustomChannel interface that we created previously. This method will be called by PostService after persisting with the blog.
To subscribe to the blog-approval topic for updating blog status, we add one method in ApprovalImpl class as shown below:
@StreamListener("BlogUpdateStatusInput")
public void subscribeBlogUpdateStatusMessage(BlogApprovalInProgress blogApprovalInProgress) {
PostPayload postPayload = postService.findByTitle(blogApprovalInProgress.getTitle()).get();
postPayload.setStatus(blogApprovalInProgress.isStatus());
postService.save(postPayload);
} Picture 14 – Method that subscribe blog-approval topic and update blog status
@StreamListener notation is used to subscribe to the certain topic in Kafka. In the above method StreamListener notation, it refers to “BlogUpdateStatusInput”. If we see in application.yml file, BlogUpdateStatusInput refers to blog-approval topic. In the method above, the blog status will be updated with status from the payload that is pulled from the blog-approval topic.
We look at /posts API in PostController. This API will be used to create Post or Blog, the blog’s status will set as false after the blog has been created successfully so the blog will not display in the home page except for passed approval processes. Posts API invoked save method from PostService class to persist the blog data. PostService calls on the publishBlogCreationMessage method to push the payload to the blog-creation topic after persisting the blog and the approval microservice will subscribe the blog-creation topic to pull the payload for further approval process.
Now, we will implement Kafka in Approval Microservice. The steps required to implement Kafka in Approval Microservice are almost the same as when we implemented Kafka in Blog Microservice. So, we will skip several Kafka config steps in this project. Approval Microservice project has responsibility to execute blog approval process; this process started on subscribeBlogCreationMessage method of KafkaMessageService class, as shown below:
@StreamListener("BlogCreationInput")
public void subscribeBlogCreationMessage(@Payload PostPayload postPayload) {
if(!blogApprovalInProgressRepository.isExistByTitle(postPayload.getTitle())){
BlogApprovalInProgress blogApprovalInProgress = new BlogApprovalInProgress();
blogApprovalInProgress.setTitle(postPayload.getTitle());
blogApprovalInProgress.setCategoryId(postPayload.getCategoryId());
blogApprovalInProgress.setCategoryName(postPayload.getCategoryName());
blogApprovalInProgress.setCreatedDate(postPayload.getCreatedDate());
blogApprovalInProgress.setSummary(postPayload.getSummary());
blogApprovalInProgress.setApprovalProgress("To Do");
blogApprovalInProgressRepository.save(blogApprovalInProgress);
}
} The method above used @StreamListener notation that refers to “BlogCreationInput”, in application.yml “BlogCreationInput” refers to the blog-creation topic. This method will subscribe to the blog creation topic and will persist for any payload which has come to the topic with approval progress value set to “To-Do” as initial value.
When /process API in ApprovalController is invoked to process approval request for certain blog id, the approval progress value will be updated to the value of @RequestParam(“progress”). There are three approval progress values: To Do, In Progress and Done, when blog admin click process buttons are shown as below:
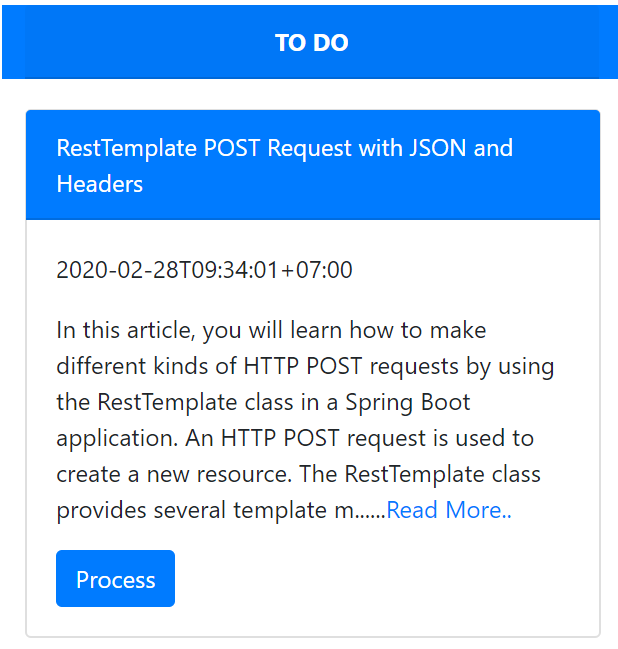
The approval progress will be updated to In Progress and then when the blog admin clicks the Approve button is shown as below:
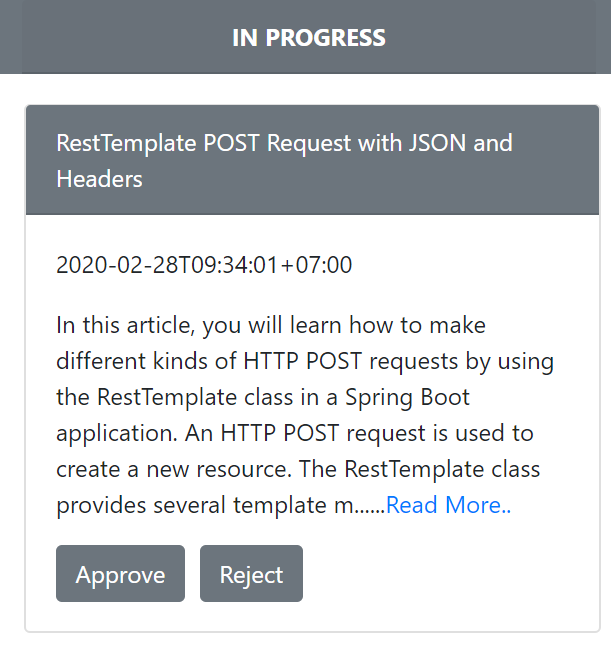
The approval progress will be updated to Done and approval status to Approved, when approval progress = Done and approval status = Approved or approval progress = Done and approval status = Rejected, approval microservice will push the payload to the blog-approval topic as the code snapshot shows below:
@PostMapping("/process")
public ResponseEntity<BlogApprovalInProgress> updateProgressStatus(@RequestParam("id") Long id, @RequestParam("status") String status, @RequestParam("progress") String progress){
BlogApprovalInProgress blogApprovalInProgress = approvalService.updateProgressStatus(id, status, progress);
if((status.equals("Approved") && progress.equals("Done")) || (status.equals("Rejected") && progress.equals("Done")) ){
kafkaMessageServices.updateBlogStatus(blogApprovalInProgress);
}
--------------------------------------------------------------------
return ResponseEntity.ok(blogApprovalInProgress);
} Blog microservice will subscribe the blog-approval topic to update its blog status. If approval status = Approved blog status, it will be updated to true and will appear in the blog home page; otherwise it remains false; this process can be seen in the code snapshot picture 14.
4. Running the Project
Now, we will run the projects to test our implementation to see whether it can run properly or not. We must run service registry first and then run config server. After that, we can run gateway, blog and approval microservice as well. Please make sure before we run blog and approval microservice, that the Kafka server has been running; otherwise, we will get “The broker may not be available” error.
After we run all backends, we can run the frontend application using npm start inside the frontend project folder; please make sure you have installed NodeJS before in your PC. After the frontend application runs, open http://localhost:3000 in the browser and then click the Sign-Up button to register the new user. To bypass email activation, we can update an enabled field in the User table to 1. Now we can login to the application using that credential. Now, we can execute the following steps:
1. Create Blog
Click the Create Blog button and then fill all required fields as shown below:
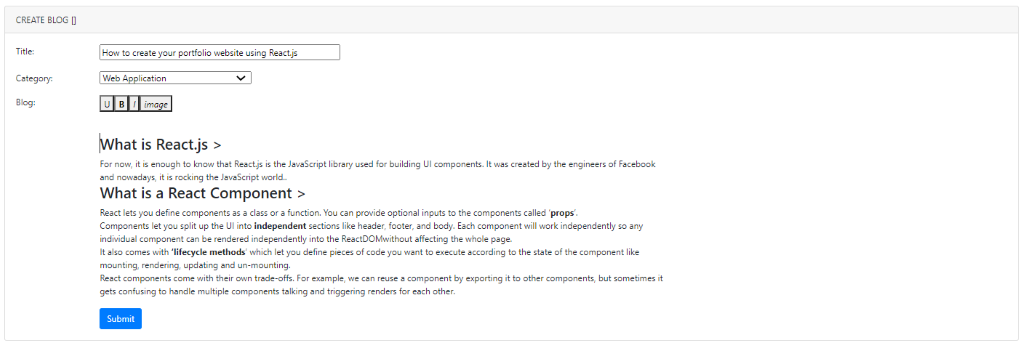
Click the Submit button to create the blog. After the blog has been created successfully, the payload will push to the blog-creation topic.
2. Check Approval Request in Blog Approval Menu
We can check the approval request in the Blog Approval menu as shown below:

3. Check Payload that Pushes to the Blog-creation Topic Using the Kafka Tool
We can check the payload that pushed to the blog-creation topic using the Kafka Tool as shown below:
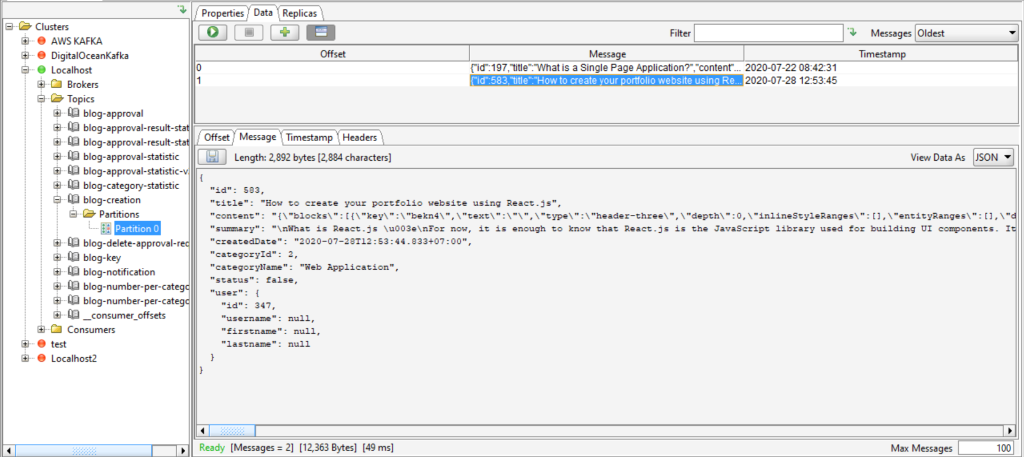
The payload appears in the blog-creation topic in offset 1 as we can see in above picture which means that our Kafka implementation can run properly.
4. Check the Payload that Persisted to the Database by Approval Microservice
Approval microservice that subscribes to the blog-creation topic will pull the payload and then persist the payload to the blog_approval_in_progress table. We can see the data in the table as shown below:
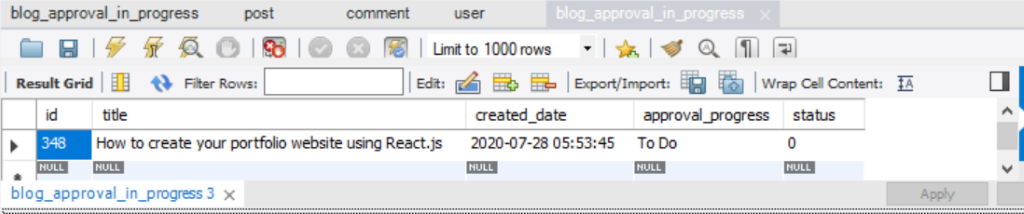
5. Process Approval Request
We can process the approval request by clicking the Process button in step no.2. After the button has been clicked, the approval progress will be updated to “In Progress” state and then the approval request will move to the In Progress section as shown below:
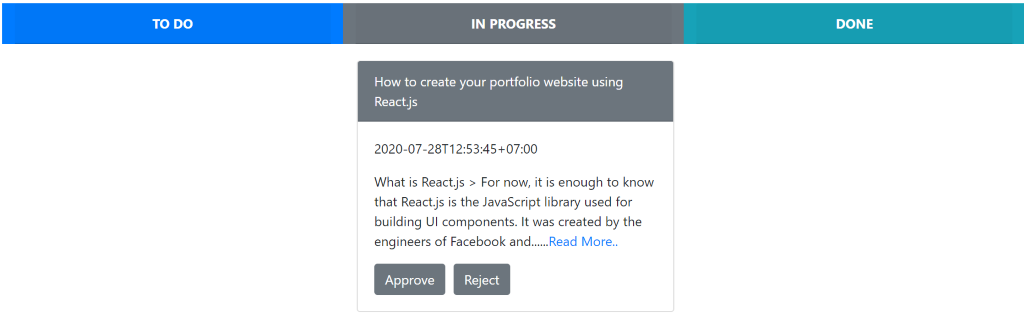
6. Approve the Blog
To approve the blog, click the Approve button. After the button has been clicked, the approval progress will be updated to Done and the approval status to Approved and then the Approval Request list will move to the Done section as shown below:

After we approve the blog, the approval microservice will push the payload to the blog-approval topic and we can see the payload in the blog-approval topic as shown below:
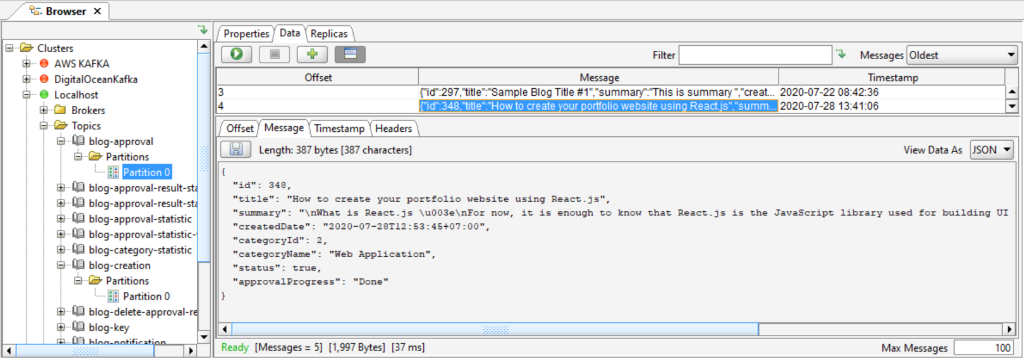
The blog microservice subscribes to the blog-approval topic and then will pull the payload, check the status and then update the field status in the post table to 1 as shown below:

After the blog has been approved, the blog will appear in the home page as shown below:
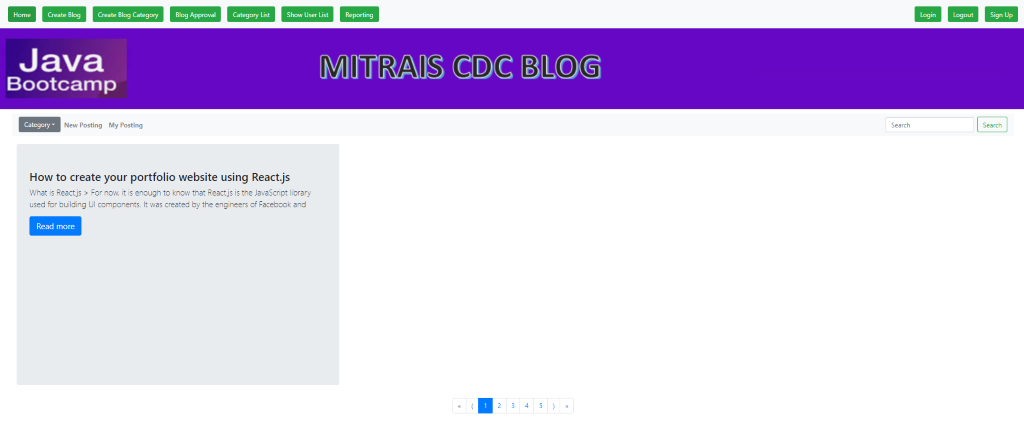
Based on the facts above, we have implemented asynchronous inter-service communication between blog microservice and approval microservice. There are several benefits if we implement asynchronous inter-service communication in microservice. The first is that inter-service communication will not block the next steps because the caller service does not need to wait for the service’s response and this will improve our service performance. The second is that it will make the microservice more resilient. For example, when the blog has been created successfully but the approval service is down, the payload that contains the approval request data will still be there in the topic and waiting for approval microservice available to pull the payload and process the approval request. This will not happen if we use http-based communication. The blog microservice will be stuck waiting for the service response and this will impact the microservice performance degradation.
IV. Conclusion
We can use asynchronous Inter-service communication to make microservice more resilient and improve microservice performance. For this purpose, Apache Kafka is the best choice to use as a messaging system in microservice. But if we want to use request-reply pattern we can use http-based communication, even though we can use Kafka in request-reply pattern with some workaround.
Author:
Syarif Hidayat – Analyst










