
Apache Kafka allows applications to share information with other applications as a distributed streaming platform. Publish-Subscribe is how Apache Kafka exchanges data between processes, applications, and servers.
Why do we need it?
Suppose we have many applications, and each one needs data from other applications. We usually send data through API to other applications to achieve that goal.
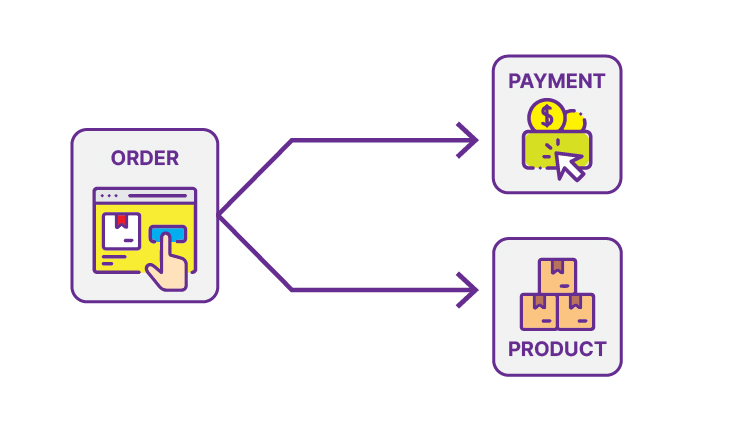
Based on the above image, Order sends a couple of applications for every transaction. What happens if, during the next update, more applications need similar data from Order? We will need some improvement to add more endpoints. Or, what if one of the endpoints is down? It will not reach one of the endpoints. To solve these problems, we can use Apache Kafka as a message broker.
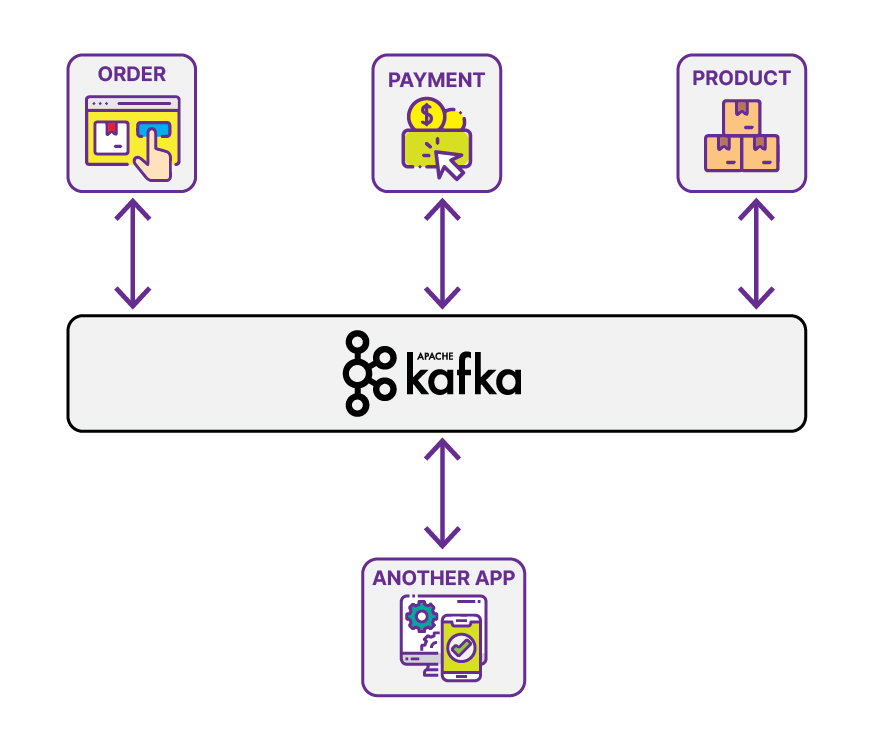
Each application only sends data to Kafka based on a topic we call Publisher in the image above. It allows all applications to reach the data by listening to a specific issue called Subscriber. The following application that needs similar data will only have to subscribe to a particular topic. As long as the data has been sent to Kafka, there is no need to improve the respective producer. In other conditions, if the producer forwarded data to the message broker while the consumer was down, Kafka will save the last data offset/position at the point where the consumer last consumed the data. When the consumer is up again, Kafka will send the data immediately.
Here are the definitions of the terms in Kafka:
- Topic
The topic is a category name to which records are stored and published. Producers are the writers for topics, and consumers read from them.
- Topic Partition
Topic Partitions contain producers’ messages where each consumer consumes the message from one topic partition. So, if five consumers subscribe to the same topic, its topic will have at least five topic partitions.
- Offset
Records exist in a partition assigned and identified by a unique offset.
- Replica
A replica is a redundant unit of a topic partition implemented at the partition level. Partitions have one or more replicas to prevent data loss. Every partition replica has one replica acting as a leader, and the rest are a follower. The leader replica handles read-write requests, and followers replicate the leader.
- Consumer Group
Consumer groups have names to identify them from other consumer groups. The primary purpose is to distribute incoming data among multiple consumers and prevent numerous consumers in consumer groups from consuming the same data.
- Retention
Time-Based Retention marks a message for deletion. The default time-based retention period is seven days. Size Based Retention configures the maximum length of a message to send to the topic partition.
Another use case that might show up is when multiple instances of the same application consume the same message and proceed. Using various instances makes a process faster but will be a problem if a notification only moves once instead of twice or more.
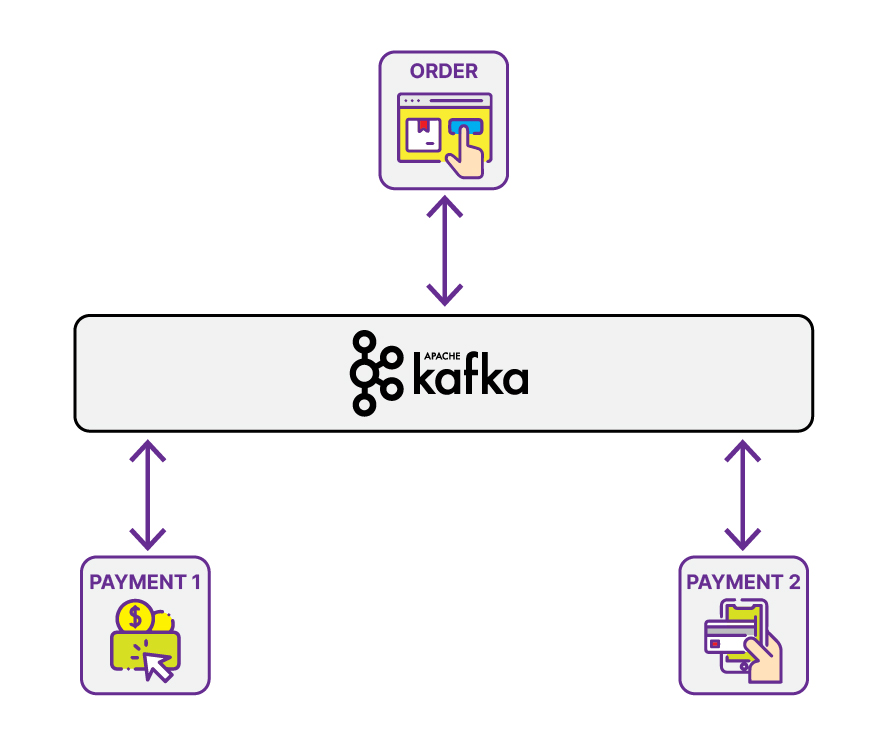
In the above image, two payment instances are needed to process the Payment from Order, and payment applications will proceed with two payments simultaneously. Kafka provides consumer grouping to prevent the message consumed two times or more by the consumer.
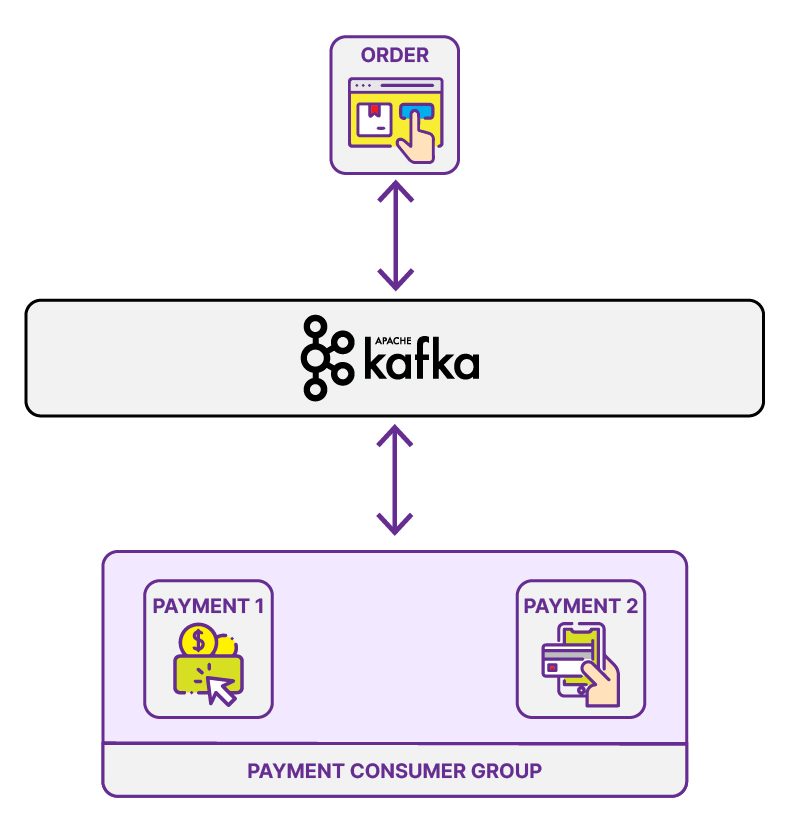
In this case, the consumer will have a consumer group name based on the transaction category. For example, let’s name it “Payment Consumer Group”. Every message sent to Kafka will be consumed by only one instance in its group.
What is the Publisher-Subscriber pattern?
Publishers are loosely coupled to subscribers. Commonly, the client cannot hit the endpoint of a particular server while its server is down. Using the Publisher-Subscriber pattern, each client can continue to operate independently. Also, in Kafka, horizontal or even vertical scaling are available. We can add more partitions to a topic for a horizontal scale when we need more subscribers to consume the message from a particular topic. We can also do vertical scale by implementing multithreading in subscribers, and each thread consumes the message from a specific partition.
Conclusion
The distributed streaming platform, Apache Kafka, helps applications to share information with other applications using Publish-Subscribe. It’s important to remember that the total number of partitions cannot be less than the consumers who subscribe to the same topic. We have discussed the general overview of Apache Kafka, but we can also implement Kafka for other purposes, such as logging and activity tracking.
Author: Handoyo, Analyst Programmer









